Zde naleznete první verzi našeho prajzsko-českého slovníku, jenž obsahuje něco málo víc než 3 000 hesel pocházející ze zdrojů, jež jsou označeny následujícími zkratkami v závorkách:
LSZ: SOCHOVÁ, Zdeňka. Lašská slovní zásoba: jihovýchodní okraj Západolašské oblasti. Praha: Academia, 2001. ISBN 80-200-0421-1.
SNOS: SKALIČKA, Vít. Slovník nářečí Opavského Slezska: okolí Opavy, Hlučínsko, předměstí Ostravy-Poruby, Nízký Jeseník a Poodří, polské příhraničí. Stěbořice: Matice slezská, 2018. ISBN 978-80-907424-0-6.
SSN: LAMPRECHT, Arnošt. Slovník středoopavského nářečí. Publikace Slezského ústavu ČSAV. Ostrava: Krajské nakladatelství, 1963.
ČJA5: BALHAR, Jan. Český jazykový atlas 5. Online. 2. Brno: Dialektologické oddělení Ústavu pro jazyk český AV ČR, 2026. ISBN ISBN 978-80-86496-95-5 (5. díl). Dostupné z: https://cja.ujc.cas.cz/CJA5/. [cit. 2025-08-20].
X: Slova a věty během let nasbírané či vytvořené mnou, Erikem Gliwitzkým.
INF1-5: Informanti, kteří se doposud zapojili do projektu a rozšířili, upřesnili či
potvrdili, co doposud ve slovníku stojí.
Slovník v žádném případě ještě není kompletní – těžiště momentální verze slovníku se nachází především na zdroji SSN, jenž byl zpracován zhruba z 20 % (písmena A až I). Na zpracování zbytku tohoto zdroje pilně pracujeme, stejně jako na zpracování ostatních uvedených zdrojů. Zároveň máme k dispozici ještě další zdroje, které jsme prozatím ještě nezpracovali – je to zdlouhavá práce, proto vás žádáme o pochopení a trpělivost.
Protože chceme, aby slovník „žil“, mají slova a příklady, jež nám poskytnete, při zpracovávání přednost. Vámi zadané údaje by se tedy měly ve slovníku projevit s každou jeho aktualizací.
Pokud se chcete do rozšiřování slovníku zapojit, můžete tak učinit tímto způsobem:
ZDE můžete doplňovat CHYBĚJÍCÍ SLOVA, UPŘESŇOVAT JEJICH SKLOŇOVÁNÍ ČI ČASOVÁNÍ atd.
ZDE můžete potvrdit, že některá z uvedených slov znáte i ze své dědiny či rodiny, nebo že je znáte v jiné podobě či výslovnosti. Potvrzování výskytu slov je pro nás důležité, abychom dokázali zachytit, kde se které slovo a v jaké podobě vyskytuje – usnadní to lidem, kteří se chtějí ponašemu naučit, dozvědět se, jak se mluví/mluvilo přímo v jejich rodné obci.
Opačný slovník (česko-prajzský) prozatím poskytnout nemůžeme, ale do budoucna jeho sestavení plánujeme.
JAK SLOVNÍK POUŽÍVAT?
Náš slovník kromě hesla (slova ponašemu) a jeho českého překladu také poskytuje informace ohledně jeho slovního druhu, gramatických pravidel a také jeho výskytu, existujících variant (totéž slovo s kupř. jinou výslovností) a synonym (jiné slovo s tímtéž významem).
České významy prajzských hesel jsou v zájmu přehlednosti očíslovány – váží se k nim synonyma a varianty, jež jsou označeny stejným číslem.
Ve slovníku vyznačujeme také informace ohledně skloňování a časování uvedených slov. Zde (tabulky připravujeme) naleznete klíč k paradigmatům všech vzorů, jež jsou ve slovníku uvedeny. Platí zde následující zásady:
- Zkratky „m.“, „ž.“ a „s.“ označují, že dané podstatné jméno je mužského, ženského nebo středního rodu. Zkratky „živ. osob.“, „živ. neosob.“ a „neživ.“ označují, že dané slovo mužského rodu je životné osobové, životné neosobové či neživotné. Zkratka „mn.“ označuje, že dané slovo je pomnožné.
- Značky u podstatných jmen označují koncovku genitivu (2. pádu) a případně také nominativu (1. pádu) plurálu (množného čísla) daného slova. Kupř.:
- jeleň, -a, pl. -ë = bez jeleňa, dva jelenë
- Případná další pravidla uvádíme hned za uvedenými značkami.
- Lomítko (/) označuje, že samohláska v koncovce odpadá, kupř.
- kaper, -/-a, pl. -’y = bez kapra, dva kapřy
- Apostrof (‚) značí, že dochází k změkčení předchozí souhlásky, kupř.:
- r + ’e → ře, k + ’y → čy
- Značky u přídavných jmen označují koncovky prvního pádu jednotného čísla u různých rodů. Kupř.:
- dłuhy, -y, -ō, -e = dłuhy [strom], dłuhō [cesta], dłuhe [słovo]
- Značky u sloves označují slovesnou třídu a koncovky 3. osoby jednotného čísla a příčestí minulé daného slovesa. Kupř.:
- druždiť, IV, -i, -ił = sloveso IV. třídy, un druždi, un druždił
- U sloves znamená zkratka dok., že se jedná o sloveso dokonavé. Zkratka nedok., že se jedná o sloveso nedokonavé.
U mnoha slov uvádíme příkladové věty, které vám mohou usnadnit pochopení významu nebo způsobu užití daného slova. Příkladové věty jsou očíslovány, abyste mohli snáz nalézt jejich český překlad, jenž se nachází v kurzivě pod příkladovými větami. Příkladové věty jsou označeny zdrojem, z něhož byly přejaty, a to v podobě (XXX), tedy kupř. (SSN) označuje, že je daná příkladová věta přejata ze Slovníku středoopavského nářečí. Hvězdička (*) udává, že dané slovo bylo uměle dotvořeno, protože se nepodařilo nalézt autentické „domorodé“ slovo o tomtéž významu.
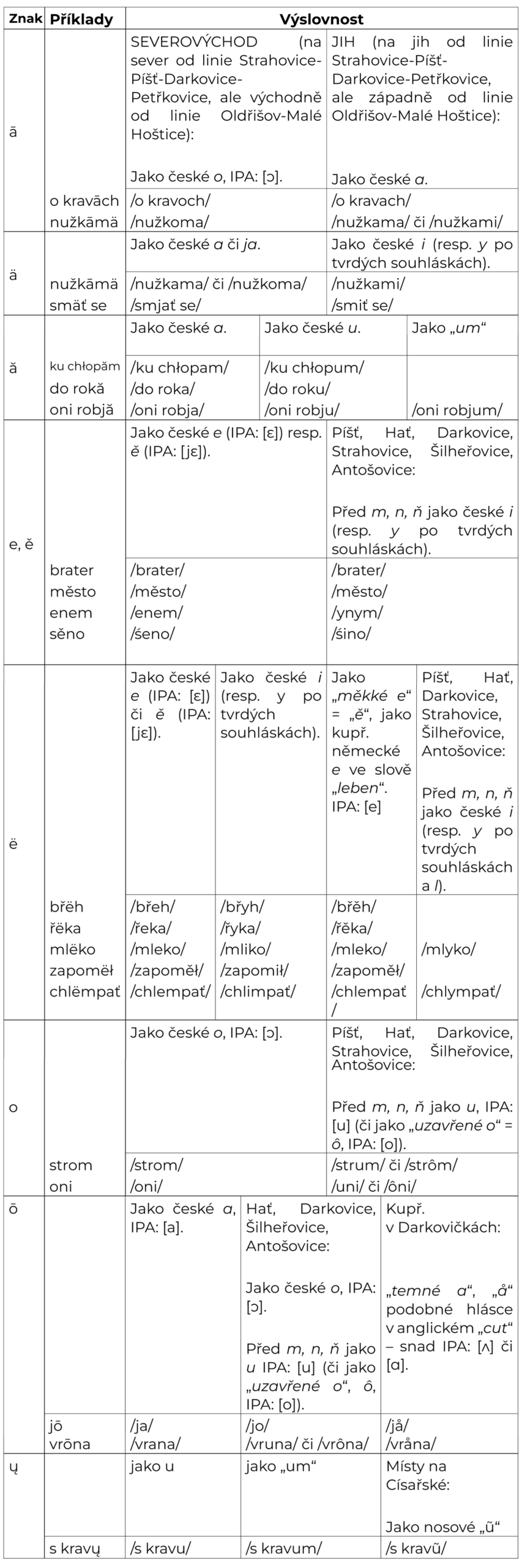
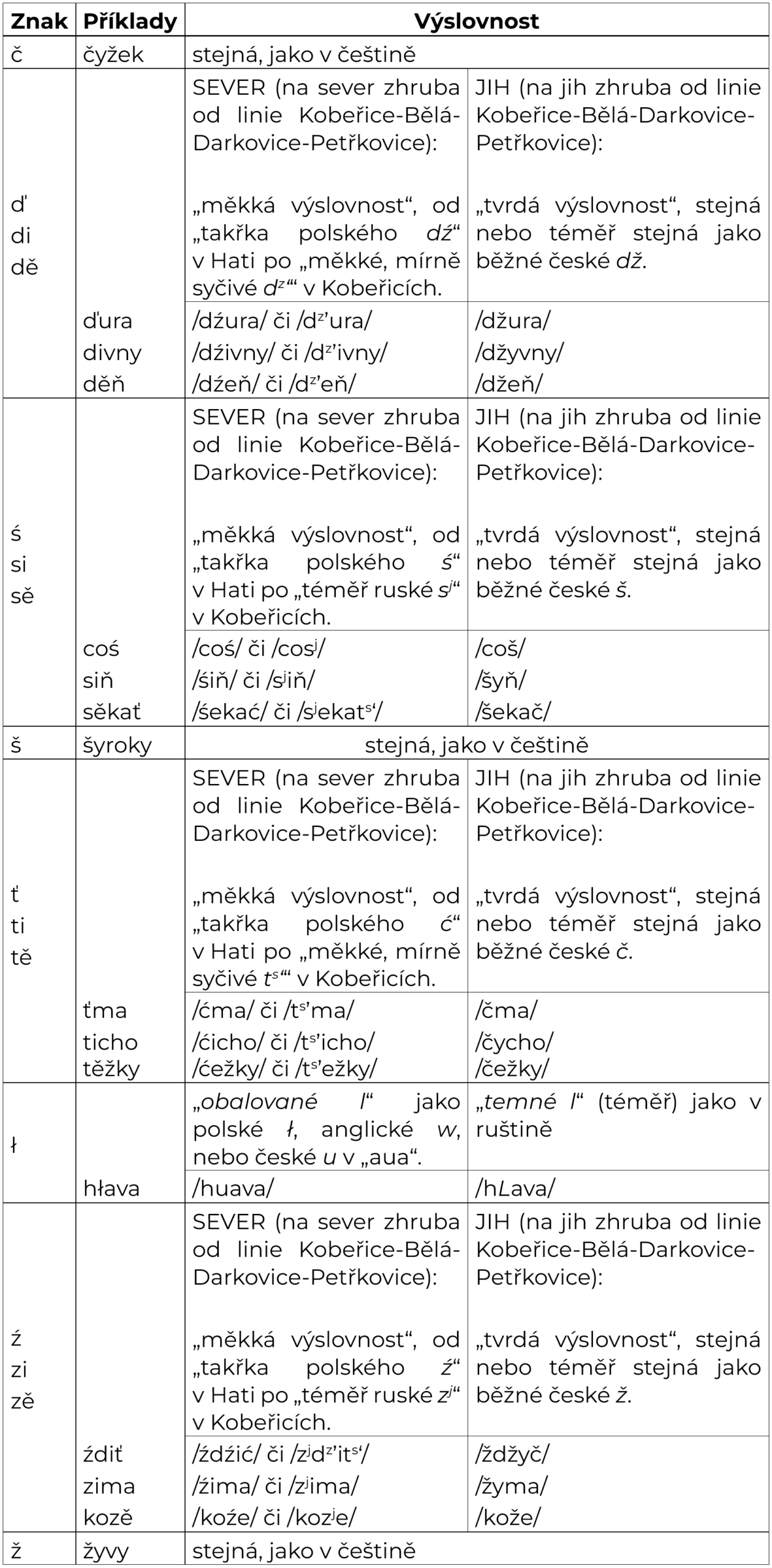
U poznámek ohledně výslovnosti užíváme zjednodušeného pravopisu, nikoliv pravopisu fonetického. Nečiníme tak z neznalosti, ale v zájmu zjednodušení pro laickou veřejnost, a také protože se hlavní rozdíl ve výslovnosti dvou variant daného slova většinou týká pouze jedné konkrétní hlásky, čímž se rozepisování všech výslovnostních variant stává nepraktickým a přebytečným.
VYHLEDÁVÁNÍ VE SLOVNÍKU
Náš slovník prozatím nemá vlastní vyhledávací systém, tento však do budoucna plánujeme. Nejjednodušší způsob vyhledávání konkrétních hesel či českých významů tedy představuje klávesová zkratka CTRL + F – po jejím stisknutí vám na obrazovce vyskočí okénko, do něhož můžete hledaný pojem či jeho část zadat, načež budete moci kliknutím na jednu ze šipek v okně nebo stisknutím klávesy Enter přeskakovat mezi místy, kde je vámi hledaný pojem uveden.
POUŽITÝ PRAVOPIS
V našem slovníku používáme tzv. kompletní pravopis, který jsem sestavil já (Erik Gliwitzký) naší mluvě tak říkaje na míru. Důvody, proč tak činíme, jsou jednoduché:
Jednotný zápis usnadňuje tvorbu slovníku i materiálů, ale také psaní v naší mluvě. Zároveň jsme se snažili, aby tímto pravopisem šlo psát tak, aby jej mluvčí naší mluvy mohli užívat, ať již dané slovo vyslovují jakkoliv. Kupř. slovo napsané jako vrōnāmä umožňuje přečíst jej tak, jak je v dané obci obvyklé Kravarákovi (/vranoma/) i Haťanovi (/vrunami/), nebo kupř. u slova ťmëť se, kde tak nemusíme rozepisovat čtyři různé výslovnosti: /čměč/, /čmič/, /ćmić/ a /ćměć/. Tento zápis samozřejmě není 100%, jedná se o kompromis, a zároveň jsme otevřeni dalším nápadům, jak jej ještě doladit a upravit tak, aby byl ještě funkčnější.
Podrobný popis toho, jak pravopis funguje, se dozvíte i v těchto videích našeho videokurzu:
Zde naleznete stručnější všeobecný přehled:
SOUHLÁSKY
SAMOHLÁSKY